[摘要]报表始终是所有信息系统中不可或缺的内容,尤其是在国内的应用系统中,报表更是占据着相当重要的地位。本文提出了一个基于jfreereport报表设计器的设计方案,并给出了基于swing的实现过程。在设计过程中主要使用了swing、xml持久化保存、mvc设计模式、软件工程等技术。
[关键词]jfreereport;报表生成;设计模式;xml持久化保存
1 基于jfreereport报表背景与简介
企业信息化过程中需要处理大量的有关多维数据集的信息,而表现数据信息处理结果的一种理想的方式就是数据报表。报表定义文件是生成复杂报表的重要文件,主要描述如何使用指定的格式生成复杂的报表,对于jfreereport定义数据报表格式所需的xml文件通常是由人工输入编写的,对于格式较为简单的报表还可以接受,但是对于大型数据库报表,数据报表关系格式复杂而且字段数量较多,人工输入易出错又繁琐,本文研究的报表设计器就是针对jfreereport报表生成内核进行开发的。
2系统整体设计
2.1系统整体框架与mvc模式
基于java的swing技术,设计器内核使用jfreereport,用于绘制和输出各种复杂的统计报表。设计器的主要工作是将用户对报表的设计意图通过报表生成内核的api传递至报表生成内核,再将报表生成的结果实时反馈给用户。报表生成后,应该能够持久化保存。此外,根据当前流行的数据库报表的功能,系统也要具备将报表转换成诸如pdf、html等其他文件格式的功能。让用户对于事实数据具有全面的分析和了解,增加数据流通为企业带来的效益。
为了能够方便地重用组件并且体现模块的独立性,把整个系统组件分解组织成11个类包,只要得到这个包文件,其他类也可以引用该包中的所有类并使用里面的某些组件。该类包分别为:datasource(数据源包),dbutilities(数据库工具包),io(磁盘操作包),jfdmainfrm(系统主窗体包),reportgenerate(报表生成包),tools(系统所需的其他工具类),wmvc(mvc包,包含有mvc模式所需的基础支持类,它是系统的底层基类)。
mvc模式的优点在于这种方法鼓励重用,而不是重新设计。有相同机理的组件,只要改写不相同的模型部分,便能制造出不同功效的组件,而不用重新设计每个组件,缩短和减轻了设计工作的时间和难度。因此选择了mvc设计模式作为系统的主体架构[1]。
mvc模式基本实现过程为:
(1)控制器;
(2)控制器新建一个或多个视图对象,并将它们与模型相关联;
(3)控制器改变模型的状态;
(4)当模型的状态改变时,模型将会自动刷新与之相关的视图。
java通过专门的类observable及observer接口来实现mvc模式。model类必须继承observable类,view类必须实现接口observer。正是由于实现了上述结构,当模型发生改变时,模型就会自动刷新与之相关的视图。其uml序列图可以表示为图1。
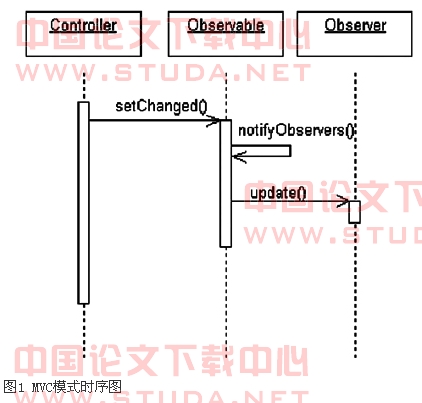
在系统具体实现时,首先建立视图类wmvcview,它继承了obsever抽象类,重载了update()和updateview()方法。然后构造模型类wmvcmodel,它继承自observable抽象类,重载了addview(),deleteview()和notifyviews()方法。通过addview()方法,模型将实例化视图并且将视图与模型建立关系。最后创建控制器wmvccontrollor类,它实现了actionlistener和itemlistener两个接口,重写actionperformed()和itemstatechanged()方法[2]。至此,系统的mvc框架搭建完成。
最后建立wmvcapp类,它应用了单例模式(singleton)来保证在整个系统中只有一个实例存在,实现了类似于vc++中的winapp机制。应用单例模式的思路是:一个类能返回对象一个引用和一个获得该实例的方法。当调用这个方法时,如果类持有的引用不为空就返回这个引用,如果类保持的引用为空就创建该类的实例并将实例的引用赋予该类保持的引用;同时还将该类的构造函数定义为私有方法[3]。这样其他处的代码就无法通过调用该类的构造函数来实例化该类的对象,只有通过该类提供的静态方法来得到该类的唯一实例。
2.2系统界面设计
整个主界面采用有限制的多文档结构。所谓有限制的多文档结构,就是同一时间内只能打开一个文档的多文档结构。为什么要这样设计而不直接使用单文档结构呢?首先,是由于jfreereport内核的限制。目前,jfreereport只支持一个报表对象在内存中,也就是说同一时间只能打开一个报表文件。因此对于设计器系统来说,同一时间当然也只能打开一个文档。但是jfreereport是一个发展很快的项目,也许它很快就能支持多文档编辑,为了保持系统的可扩展性,所以选择了多文档结构。其次,在系统界面中还引入了子菜单的概念,通过在子窗体上构造子菜单,将报表菜单与系统菜单分离,使得主界面更加简约,用户操作简便。
系统界面主要分为以下几个区域:
(1)系统菜单:用户通过它进行保存/打开报表、设置数据源等系统操作;
(2)报表菜单:用户通过它对报表进行格式转换、打印、翻页、比例设置等操作;
(3)报表工具条:提供报表菜单常用项的快捷操作;
(4)编辑浏览域:编辑报表时实时显示编辑效果;
(5)编辑状态条:显示报表页数等状态信息。
报表元素编辑区:报表编辑的主要区域,以分区域的方式显示报表元素的简要信息。并提供对于报表元素添加、删除、修改功能的操作方法。
2.3数据库连接类的设计
java的数据库编程主要使用jdbc类库。使用jdbc类库进行编程,调用connection.getconnection()方法时,获得一个connection对象,并使用正面(facade)模式来实现jdbc编程[4]。
dbfacade是一个facade对象,它使用execute()和executequery()两种方法执行sql语句。前者执行数据库操作语句,后者执行数据库查询语句。在dbfacade类中包装了两个对象,sqlstatement和connectionmgr。sqlstatement类主要实现sql语句的查询,connectionmgr类实现了一个单例(singleton)模式,用于管理与数据库的连接。
3报表部件的实现
3.1报表表板的定义
为了方便用户设计报表,系统中的报表模板是由若干个表板组成的,而各报表元素,位于各表板之中。模板、表板、报表元素。
系统支持的7类表板如下:
页眉板(pageheader)、表眉板(reportheader)、组眉板(groupheader)、主体板(itemband)、组脚板(groupfooter)、表脚板(reportfooter)、页脚板(pagefooter)等。
3.2报表编辑的功能
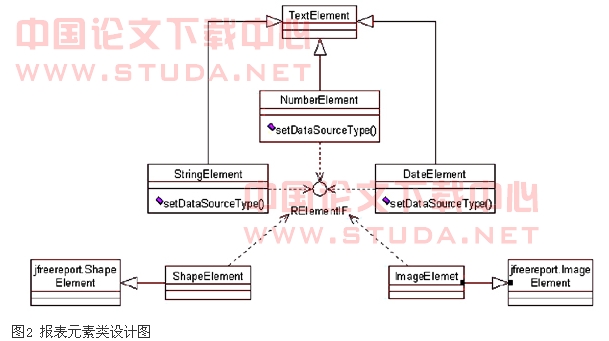
为了实现报表的编辑功能,系统将报表元素组织成一棵元素树。所以报表编辑功能的实现首先要构造元素树[5]。为了完成元素树的构造,必须设计一个机制来识别报表中的元素。由于jfreereport本身定义的报表元素类型比较简单,不便于用户编辑报表,对于jfreereport的报表元素类型进行了扩展。系统中的报表元素共有5种类型:stringelement(文本元素),它是报表中最常用的元素类型,分为域绑定型和静态型;numberelement(数值元素),是一个域绑定型元素,用于存放数值格式信息,可以设置数值的显示格式;dateelement(日期元素),属于域绑定型元素,存放日期信息,且可以设置日期的显示格式;shapeelement(图形元素),矩形、直线等矢量图形用图形元素表示;imageelement(图片元素),用于存放外部的图片。
由于对jfreereport的元素类型进行了扩展,就需要对元素类进行重新设计。目前,只有stringelement支持静态类型数据,为了保持系统的可扩展性,构造了一个relementif接口用于保存元素的类型信息。stringelement、numberelement和dateelement在jfreereport中都属于textelemet,所以它们都继承了textelement类,通过setdatasourcetype()方法来应用不同的格式模版,完成类的扩充。在识别报表元素时只需对relementif对象进行instanceof运算,即可获知当前的报表元素。图2展示了系统报表元素的类设计图。
3.3报表定义文件的存取
系统的最终目的是自动生成jfreereport的数据报表定义文件,因此有必要将数据源信息与数据报表的定义分开保存。这样就可以实现数据与样式展示的分离。为此,系统引入了工程的概念:将数据报表的样式定义信息和数据源信息分别持久化保存,再用一个工程文件保存上述两个文件的路径。
jfreereport提供了报表定义文件输出的api方法[6],由于数据源对象是一个javabean类,可以使用xmlencoder和xmldecoder类库方法将其序列化,限于篇幅,源码不再列出。
4结语
报表问题是企业信息化过程中关注的一个焦点,它的难点在于实现客户化,本文中介绍了一个基于jfreereport的报表生成器的一个设计过程,并给出了设计jfreereport报表生成器的关键步骤。目前的系统实现了jfreereport主要功能。随着jfreereport的系统应用范围扩大,还有待于在以下方面完善[7]:
(1) 继续加强设计器的功能,实现更丰富的报表模版(比如子从报表、套打报表等),并加强图表功能。
(2) 设计基于jfreereport的服务器端,实现报表的网络发布。
[参考文献]
[1] bruce ewampler.java与uml面向对象程序设计[m].北京:人民邮电出版社,2002:127-130.
[2] tom myers,alexander nakhimovsky.java xml编程指南[m]. 北京:电子工业出版社, 2001 :379-382.
[3] john o’donahue.java数据库编程宝典[m]. 北京:电子工业出版社,2003 :57-61.
[4] mark graves.xml 数据库设计[m]. 北京:机械工业出版社,2002 :330-335.
[5] karl ewiegers. personal process improvement[j]. software development magazine, 2000 :21-23.
[6] 施伯乐,丁宝康.数据库技术[m].北京:科学出版社 2002:276-279.
[7] 何新贵.软件能力成熟度模型[m]. 北京:清华大学出版社,2001:167-169.