内容摘要:异常点挖掘是数据挖掘的一项功能,现有的文献较多关注于算法及其改进方面,而对于异常点挖掘过程以及如何将异常点挖掘应用于证券业缺乏深入研究。本文针对上述两个问题展开探讨,提出异常点挖掘的生命周期模型并给出该模型在证券业的应用案例,为应用的研究提供参考。
关键词:证券业异常点 数据挖掘 应用
证券业是一个数据密集型的行业,经过多年的发展,许多券商积累了海量的客户数据。如何挖掘这些宝贵的数据资源以发现证券交易过程中隐含的不良操作,是数据挖掘在证券行业应用的重要课题。对于异常点, hawkwins认为:一个异常点是这样一个测量值,它过分地偏离其他测量值,从而使人们对它产生怀疑,怀疑它是由不同的机理产生的。作为数据挖掘的一项功能,异常点挖掘受到众多学者的重视,但大部分的研究重点均放在算法、算法优化和改进等方面,而对异常点挖掘过程以及如何结合具体的问题域、行业背景知识进行挖掘则探讨不多。
异常点有着较强主观性,在进行异常点挖掘研究时应定义特定的挖掘背景。在证券业,异常点挖掘可以发现客户数据中的异常点或者孤立点,而这些特殊数据恰恰包含了非正常的交易。当然,并不是所有的异常点都是不良操作或者违规交易,其中,有一部分异常点可能是噪音数据,有些则是真实的并且有利于券商的交易信息,例如,发现大客户或者潜在的优质客户等。基于此,本文将重点探讨完整的异常点挖掘流程及其在证券业的应用。
异常点挖掘的生命周期过程
异常点挖掘的生命周期应该包括定义目标、选择数据源、选择挖掘算法、设置初始维(组合)及域值、计算验证、迭代以及后期分析7个步骤(如图1)。
定义挖掘目标。从数据挖掘的七个步骤来看,定义目标应该是一张宽泛的、粗线条的需求定义列表,例如:对客户交易记录进行异常点挖掘,找到异常交易和可疑记录;发现不同类型客户分组中的特例,等等。
选择数据源。异常点挖掘和数据挖掘的数据源一般来说是一致的,并在其基础上根据挖掘目标进行选择和预处理。此外,为了获得更佳的挖掘效果,需要对进行异常点挖掘的数据源做预处理。大部分情况下,这类数据源的预处理将在任务开始时完成,并且可以直接运用到异常点挖掘中。
选择算法。涉及异常点挖掘的算法较多,比较常用的有基于统计的算法、基于距离的算法、基于偏差的算法,每种算法都有不同的实现。在实践中需要针对不同的挖掘目标,不同的数据源,不同的资源条件,对算法做出选择和优化。
维和初始参数的选择。在异常点挖掘时,证券客户不同的维(属性)组合得到的异常点可能完全不同。有些记录在某些维度上的偏差较大,当计算包括这些维度时,往往会覆盖其他维对异常点判断的影响,而不考虑这些维时,这些点并不表现得多么“异常”。因此,需要单独考察某些维度组合上的异常情况;同时,也需要在过滤掉那些过于“异常”的维度和记录之后,考察其余维度上的异常情况。除了维度的选择,在开始计算时,也要考虑域值的初始值设置。对于基于距离的异常点挖掘算法,邻域阀值k的取值非常关键,尤其对于局部异常点挖掘,k的不同取值可能产生完全不同的结果。
计算并验证异常点。挖掘算法的实现可以借助一些统计分析工具,例如sas、spss等,或者是自己实现挖掘算法。相比计算,验证异常点就要困难得多,首先必须保证算法的实现是正确的,其次即使使用一个可靠的程序进行挖掘时,仍然可能会有误差和噪音干扰挖掘结果。一个办法是通过迭代计算比较多次结果后剔除,而迭代是整个异常点挖掘过程的一个必须环节;另一个办法是观察异常点数据的特征,当数据是低维(小于3维)时可以使用散点图观察样本分布,通过直观比对挖掘得到的异常点位置来判断有效性。
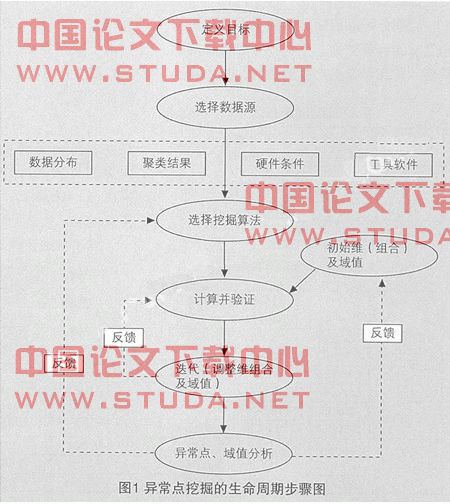
迭代计算(调整维组合和域值)。一次异常点挖掘的结果,并不意味着挖掘过程的结束,还需要调整维组合和域值之后迭代计算,得到更全面和系统的结论。例如,对于一个基于佣金和交易次数两个维度组合得到的异常点,我们认为它是在维度组合[佣金,交易次数]上的异常点,而对于其他维度组合则不一定,或者还有更加“异常”的样本点存在。对于不同维度组合下的综合考察可以帮助我们找到更加“合格”的异常点,迭代计算可以帮助我们完成这项任务。异常点的计算是一个动态的过程,从初始的维组合和参数设置开始,需要制定一个有条理的维组合选择计划,每次计算选择不同的维组合进行计算,同时验证所得的异常点是否有效,以决定域值和维的选择。一旦对数据进行了若干轮挖掘并获得输出结果后,便可据此进行后期分析和目标检验。
后期分析。后期分析的主要任务是综合之前的计算结果,结合挖掘目标和问题背景,解释异常点产生的原因,指出需要采取的措施和方案建议等。为了对异常点做出合理解释,需要结合行业知识和其他外部信息,包括专家知识、相关规范标准、行业平均水平等作为参考。因此,异常点挖掘结果应该是一份全面描述挖掘过程,对结果进行综合分析,并加入与目标相适应的解决方案和建议。
应用分析
定义挖掘目标。本案例以异常点挖掘生命周期模型为指导,通过异常点挖掘,帮助券商发现客户的(潜在)异常交易行为。具体包括两方面的作用:一方面作为客户细分结果的验证,找到每个客户组群上的边缘客户,为聚类分析结果提供验证和补充,另一方面,通过异常点挖掘标记出每个组交易异常的客户。
客户数据取自某证券公司营业部某年度的客户交易数据,涉及客户21580人,客户属性经处理后选取用户id、交易总量、佣金、交易次数、资金量、股票成交数、股票变动次数、资金变动次数、年龄、开户时长,其中用户id、年龄和开户时长未参与计算。
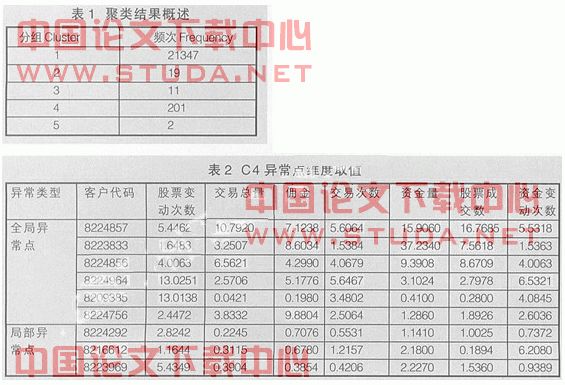
选择数据源。聚类分析为异常点挖掘提供了数据预处理,使得挖掘能够更加精确和高效。实际操作中,直接使用聚类获得的结果作为异常点挖掘的客户分组,记为c1、c2……c5(聚类过程略)。表1列出了聚类结果。由于c2、c3和c5样本数量太小,异常点挖掘意义不大,故不参加计算。
选择算法。考虑到数据源、软硬件条件以及时间限制等因素,本案使用基于距离的算法进行异常点挖掘;在验证异常点时,使用统计偏差监测方法进行异常点检验。
维和初始参数的选择。在本案中,通过对维组合和域值的设置、不断进行迭代和尝试,通过对结果的观察,最后一次计算的维组合是[佣金、交易次数、股票变动次数、资金变动次数],其中佣金和交易次数是原始变量,而股票变动次数和资金变动次数是两个复合变量,由聚类之前的数据预处理得到;对于域值k,根据试验以及考虑到性能的代价,取k=15进行计算。
计算并验证异常点。当确定了挖掘目标、数据源、挖掘算法、初始维组合和域值之后,就可以进入计算和验证过程。
迭代计算。最后,把不同维组合计算出的异常点进行综合,可以得到该数据集所有的异常点。对于c4(c1略),最后综合得到的异常点在各个维度上的取值(如表2)。
后期分析。该阶段需要对比计算结果和最初定义的挖掘目标,根据异常点的数据特性解释其异常原因,并且总结出那些潜在的知识和规律。表2列出了c4群组中所有的异常点及其表现,对比异常点和该维度上的均值可以得到一个简单的分析结果。对于局部异常点,即表2中列出的客户8224292、8216612和8223969,较难对其做出一个直观合理的解释,但在某些情况下,局部异常点恰恰是那些潜在的、被忽视的数据或者线索。例如8216612客户,可以看到他的资金变动次数远高于均值,而其他对应的股票操作都接近均值,因此,不能排除其频繁通过股市进行资本操作甚至是风险或者非法操作,而这些需要券商作进一步的分析。通过对异常点的分析,券商可以深入了解这些客户的交易行为特征,为开展精细化营销提供科学依据。
综上,异常点挖掘一直以来得到众多学者的关注,但现有的研究过多关注算法及其优化方面,而对其在具体行业的应用探讨不够。本文在论述中首先提出异常点挖掘生命周期模型,并以一个证券客户数据异常点挖掘为例阐述了该模型的应用,为相应的研究提供参考。
参考文献:
1.王宏鼎,童云海等.异常点挖掘研究进展[j]. 智能系统学报,北京,2006(3)
2.[美]拉德著,朱扬勇等译.数据挖掘实践[m].机械工业出版社,2003
3.马超群等.金融数据挖掘[m].科学出版社,2006