�������Ĺؼ��ʣ�b/s�ṹ����������硡���ݿ⡡sql���ԡ�jsp��web������
��������ժҪ�����Ľ�Ϲ�����ѯϵͳ��ʵ����Ҫ��ͨ����b/sģʽ��jdk�������������ߡ�web�����������ݿ��Լ�sql���Ե�����ѧϰ��ʵ������Ҫ����˹�����ѯϵͳ��������������ݿ���ơ�Ӧ�ó�����ƵĹ�����
������һ�� �� ��
������1.1���ݿ⼼��
�������ݿ⼼����Ϊ���ݹ����������Ǽ�������������һ����Ҫ��֧��������60���ĩ�������γ��൱��ģ��������ϵ��ʵ�ü�������������ݿ������Ӧ�óɹ��Ļ�ʯ�������ɸ�¥ƽ�������ݿ������ͬ��¥�Ļ�ʯ���ǿ�����Ʒ��Ӧ�õ�ǰ�ᡣ
����1.1.1���ݿ����ϵͳ��dbms��
���ݿ����ϵͳ��dbms����ָ���ݿ�ϵͳ�й������ݵ�����ϵͳ��dbms�����ݿ�ϵͳ�ĺ�����ɲ��֡������ݿ��һ�в������������塢��ѯ�����¼����ֿ��ƣ�����ͨ��dbms���еġ�
�ڲ�ͬ�ļ����ϵͳ�У�����ȱ��ͳһ�ı�����ʹͬ������ģ�͵�dbms���������û��ӿڡ�ϵͳ���ܷ���Ҳ�����Dz���ͬ�ġ�
�û������ݿ���в���������dbms�Ѳ�����Ӧ�ó�������ⲿ����������ٵ����ڲ��������������洢���е����ݡ�dbms����ҪĿ�꣬��ʹ������Ϊһ�ֿɹ�������Դ������
������1.2 ������ѯϵͳ
����1.2.1ϵͳ����
����1�������������b/sģʽ���Ĺ�����·�����ѯ��
����2�����ݵ�¼�롢�ġ����ӡ�ɾ����
����1.2.2ϵͳ���л���
��ϵͳ����browser/serverģʽ������ƣ� �ڷ�����������web���������������ݿ������������ϵͳΪwindowsnt/2000/xp/2003 server���ͻ�������Ϊwindows9��/ nt/2000/xp/2003������������������������Ϳͻ�����Ϊͬһ�豸��
����1.2.3ϵͳ��������
������ϵͳ����jdk java�������п��������ݿ������Ϊmysql��web����������Ϊtomcat server���ͻ���ʹ����������г�������ϵͳ���Գɹ���
������1.3 ������������
�������Ƚ����˳��й�����ѯϵͳ��Ӧ�ñ��������������Լ�ѡ�õĿ������������ݿ�Ĺ�ϵ�������˼������������ĸ���������ݿ����ϵ�ṹ��dbms�����˽��ܣ����ܹ�ϵ�����ݿ�Ļ����������˵���˼����ؼ�����Ķ��壻Ȼ���sql��������һ������˵�������ص�������֣�����java��jsp�����ҽ�����b/sģʽ�ĸ���ص㣻���������̵ķ����������й�����ѯϵͳ��������ϵͳ�������������������ģ�黮�֣���ͨ��erͼ�����ݿ���и�����ƣ��Գ��й�����ѯϵͳ�ľ�����ƣ������˲�ѯ��¼��ģ���ʵ�ֹ��̡�
�����ڶ��� ���ݿ����ۻ���
������2.1 ��ϵ�����ݿ�
����2.1.1���ݿ���������
������ϵ���ݿ�����������Ҫ����������������ݣ�������������ʽ��ģʽ��Ʒ��������������������ź��ĵ����á�
����1. ����������functional dependency , fd���Ķ���
������r(u)��һ����ϵģʽ��u��r�����Լ��ϣ�x��y��u���Ӽ�������r(u)���κ�һ�����ܵĹ�ϵr�����r�в���������Ԫ�飬������x�ϵ�����ֵ��ͬ������y�ϵ�����ֵ��ͬ����ơ�y����������x�� ������x��y�����x��y�����Ҷ���x����һ���Ӽ�x ��������y ������������x ������ơ�y��ȫ����������x�� ������x f y ����x��y����y����ȫ����������x����ơ�y���ֺ���������x�� ������x p y �����x��y��y��z����y�� x�� x������������y����ơ�z���ݺ���������x����
����2. ��ʽ
�����ڶԱ�����ʽ�����˹淶����������ݽṹ�������ֹ淶�����壬����Ϊ�淶��ģʽ����Ϊ��ʽ���������ַ�ʽ�У�һ��ֻ��ǰ���֣����ڳ���ϵͳ���㹻�ˡ����������ַ�ʽ�ǡ����ϼ��ݡ��ģ���������巶ʽ�����ݽṹ�Զ�����һ�����������ķ�ʽ��������ķ�ʽ�����ݽṹ�Զ������һ����������ʽ���������������ơ�
����Ϊ��ֹ���ݿ���ָ����쳣�������쳣��ɾ���쳣����������̫�������ϵ�����ݿ�Ҫ��������ϵ�淶��Ҫ��������ݿ���ơ�
����3. ģʽ��Ʒ���
����һ���õ�ģʽ��Ʒ���Ӧ������������ԭ��
���������ԣ��漰���������ݿ�ģʽ�ĵȼ������⣬�����ݵȼۺ������ȼۣ��ֱ����������Ӻͱ��ֺ���������������
���������ԣ���ָ���Լ�ġ�������ϵ��Ӧ���ò�ͬ�Ĺ�ϵģʽ���������ϵ�����������ǵġ�������Ϣ��λ����ʵ���Ϸ����������洢�쳣������������������ܴﵽ���Ŀ�ģ��ͷ��롣����Ļ�����һϵ�з�ʽ�������������ȼ���ʱ�Dz��ɼ��ݵġ�
������С�����ԣ�Ҫ���ڷֽ������ݿ��ܱ���ԭ�����ݿ��������Ϣ���ǰ����ʵ�֡�Ŀ�ľ��ǽ�ʡ�洢�ռ䣬��߶Թ�ϵ�IJ���Ч�ʣ��������Ҫ�����ࡣ��Ҫע�⣬��ʵ��ʹ���У�����һ��Ҫ�ﵽ��С���ࡣ��Ϊ��ʱ����������ڲ�ѯ�������кô��ġ�
������ϵģʽ�ķ��������Ͽ��Է�Ϊ�ֽ���ϳ������ࡣ�ֽ����㷨Ҫ������һ����ʼģʽ������������������������ݵȼ�Ҫ���ںϳ����㷨ֻҪ�������ʼ���������������������Ҫ���������ݵĻ���˼���ǹ�ͬ�ģ�����������ϵ������ʾ��
����sql��structured query language�������ṹʽ��ѯ���ԡ���sql��Ȼ��Ϊ��ѯ���ԣ���ʵ���Ͼ��ж��塢��ѯ�����ºͿ��Ƶȶ��ֹ��ܡ�������ʹ�÷��㡢���ܷḻ�����Լ���ѧ���ܿ�õ�Ӧ�ú��ƹ㡣
����2.2.1 sql�����
����sql��Ҫ�ֳ��ĸ����֣�
����1�����ݶ��壺��һ����Ҳ��Ϊ��sql��ddl�������ڶ���sqlģʽ������������ͼ��������
����2�����ݲ��ݣ���һ����Ҳ��Ϊ��sql��dml��������Ϊ���ݲ�ѯ�����ݸ������ࡣ�������ݸ����ֳַɲ��롢ɾ�����������ֲ�����
����3�����ݿ��ƣ���һ���ְ����Ի���������ͼ����Ȩ�������Թ����������������Ƶ����ݡ�
����4��Ƕ��ʽsql��ʹ�ù涨����һ���������漰��sql���Ƕ�����������Գ�����ʹ�õĹ���
����2.2.2 sql�����ݲ�ѯ
����n select�����
����select��Ŀ������������б���ʽ����
����from���������ͣ�����ͼ����
����[where����������ʽ]
����[group by��������
����[having����������ʽ]]
����[order by����[asc|desc]��]
�����䷨��[]��ʾ�óɷֿ��У�Ҳ���ޡ�
������������ִ�й������£�
����a) ��ȡfrom�Ӿ��л���������ͼ�����ݣ�ִ�еѿ�����������
����b) ��ȡ����where�Ӿ��и�������������ʽ��Ԫ�顣
����c) ��group�Ӿ���ָ���е�ֵ���飬ͬʱ��ȡ����having�Ӿ�������������ʽ����Щ�顣
����d) ��select�Ӿ��и������������б���ʽ��ֵ�����
����e) order�Ӿ�������Ŀ���������������˵��asc�������У���desc�������С�
����select����У�where�Ӿ��Ϊ���������Ӿ䡱��group�Ӿ��Ϊ�������Ӿ䡱��having�Ӿ��Ϊ���������Ӿ䡱��order�Ӿ��Ϊ�������Ӿ䡱��
����2.2.3 sql�����ݸ���
����sql�����ݸ��°������ݲ��롢ɾ�����ĵ����ֲ���
����1�����ݲ���
����a) Ԫ��ֵ�IJ���
����insert��into��������������������
����values��Ԫ��ֵ��
�������ߡ�insert��into��������������������
��table��Ԫ��ֵ����
����������Ԫ��ֵ����
��������������)
����ǰһ�ָ�ʽֻ�ܲ���һ��Ԫ�飬��һ�ָ�ʽ���Բ�����Ԫ�顣
����2������ɾ��
����sql��ɾ��������ָ�ӻ�����ɾ��Ԫ�飬������£�
����delete��from����������
����[where��������ʽ]
�����������Ǵӻ�������ɾ��������������ʽ��Ԫ�顣
����3��������
��������Ҫ�Ļ�������Ԫ���ijЩ��ֵʱ��������update���ʵ�֣���䷨���£�
����update����������
����set��������ֵ����ʽ[��������ֵ����ʽ��]
����[where��������ʽ]
�����������ǣ��Ļ�������������������ʽ����ЩԪ���е���ֵ�����ĵ���ֵ��set�Ӿ���ָ����
���������� ��������
������ sun ��ʽ���� jsp(javaserver pages) ֮�������µ� web Ӧ�ÿ��������ܿ����������ǵĹ�ע��jspΪ�����߶ȶ�̬�� web Ӧ���ṩ��һ�����صĿ������������� sun ��˵���� jsp �ܹ���Ӧ�г��ϰ��� apache webserver �� iis4.0 ���ڵ� 85% �ķ�������Ʒ��
����3.1.1 jsp�����
�� sun ��˾�� jsp ��ҳ�Ͽ������� jsp �淶����Щ�淶�����˹�Ӧ���ڴ��� jsp ����ʱ��������ӵ�һЩ����
�� ������jspʾ��ҳ��֮ǰ��Ҫע�ⰲװjswdk��Ŀ¼���ر��ǡ�work����Ŀ¼�µ����ݡ�ִ��ʾ��ҳ��ʱ������������� jsp ҳ����α�ת���� java Դ�ļ���Ȼ���ֱ������class�ļ�����servlet����jswdk�������е�ʾ��ҳ���Ϊ���࣬���ǻ�����jsp�ļ��������ǰ���һ��������html�ļ�����Щ��������jsp���봦������aspһ����jsp�е�java������ڷ�������ִ�С���ˣ����������ʹ�á��鿴Դ�ļ����˵���������jspԴ����ģ�ֻ�ܿ������html���롣����ʾ����Դ�����ͨ��һ�������ġ�examples��ҳ���ṩ��
����3.1.2 jspҳ��ʾ��
�����������һ���� jsp ҳ�档������ jswdk �� examples Ŀ¼�´�������һ��Ŀ¼��Ŵ��ļ����ļ����ֿ������⣬����չ������Ϊ.jsp��������Ĵ����嵥�п��Կ�����jspҳ����˱���ͨ html ҳ���һЩ java �����⣬���߾��л�����ͬ�Ľṹ��java������ͨ�� < % �� %> ���ż��뵽 html �����м�ģ�������Ҫ���������ɲ���ʾһ���� 0 �� 9 ���ַ�����������ַ�����ǰ��ͺ��涼��һЩͨ��html����������ı���
�� < html>
�� < head>< title>jsp ҳ�� < /title>< /head>
�� < body>
�� < %@ page language="java" %>
�� < %! string str="0"; %>
�� < % for (int i=1; i < 10; i++) {
�� str = str + i;
�� } %>
�� jsp ���֮ǰ��
�� < p>
�� < %= str %>
�� < p>
�� jsp ���֮��
�� < /body>
�� < /html>
������� jsp ҳ����Էֳɼ���������������
�������������� jsp ������ jsp �������Կ����Ƕ�������һ��εı����ͷ����ĵط��� jsp ������ < %! ��ʼ�� %> �������籾���еġ� < %! string str="0"; %> ��������һ���ַ�����������ÿһ�������ĺ��涼������һ���ֺţ���������ͨ java ����������Ա����һ����
����λ�� < % �� %> ֮��Ĵ���������� jsp ҳ�洦������ java ���룬�籾���е� for ѭ����ʾ��
�������λ�� < %= �� %> ֮��Ĵ����Ϊ jsp ����ʽ���籾���еġ� < %= str %> ����ʾ�� jsp ����ʽ�ṩ��һ�ֽ� jsp ���ɵ���ֵǶ�� html ҳ��ļ�����
�����Ự״̬ά���� web Ӧ�ÿ����߱�����Ե����⡣�ж��ַ��������������������⣬��ʹ�� cookies �����صı���������ֱ�ӽ�״̬��Ϣ���ӵ� url �С� java servlet �ṩ��һ���ڶ������֮�������Ч�ĻỰ���ö��������û��洢����ȡ�Ự״̬��Ϣ�� jsp Ҳͬ��֧�� servlet �е�������
������ sun �� jsp ָ�� �п��Կ��������й����������˵���������ĺ����ǣ���Щ�������ֱ�����ã�����Ҫ��ʽ��������Ҳ����Ҫר�ŵĴ��봴����ʵ���������� request �������� httpservletrequest ��һ�����ࡣ�ö�������������йص�ǰ������������Ϣ������ cookies �� html ���������ȵȡ� session ����Ҳ������һ������������������ڵ�һ�� jsp ҳ�汻װ��ʱ�Զ����������������� request �����ϡ��� asp �еĻỰ�������ƣ� jsp �е� session ���������Щϣ��ͨ�����ҳ�����һ�������Ӧ���Ƿdz����õġ�
����Ϊ˵�� session ����ľ���Ӧ�ã�����������������ҳ��ģ��һ����ҳ��� web Ӧ�á���һ��ҳ�棨 q1.html ��������һ��Ҫ�������û����ֵ� html �������������£�
< html>
< body>
< form method=post action="q2.jsp">
����������������
< input type=text name="thename">
< input type=submit value="submit">
< /form>
< /body>
< /html>
�����ڶ���ҳ����һ�� jsp ҳ�棨 q2.jsp ������ͨ�� request ������ȡ q1.html �����е� thename ֵ�������洢Ϊ name ������Ȼ����� name ֵ���浽 session �����С� session ������һ������ / ֵ�Եļ��ϣ���������� / ֵ���е�����Ϊ�� thename ����ֵ��Ϊ name ������ֵ������ session �����ڻỰ�ڼ���һֱ��Ч�ģ�������ﱣ��ı����Ժ�̵�ҳ��Ҳ��Ч�� q2.jsp ������һ��������ѯ�ʵڶ������⡣���������Ĵ��룺
< html>
< body>
< %@ page language="java" %>
< %! string name=""; %>
< %
name = request.getparameter("thename");
session.putvalue("thename", name);
%>
���������ǣ� < %= name %>
< p>
< form method=post action="q3.jsp">
��ϲ����ʲô ?
< input type=text name="food">
< p>
< input type=submit value="submit">
< /form>
< /body>
< /html>
����������ҳ��Ҳ��һ�� jsp ҳ�棨 q3.jsp ������Ҫ��������ʾ�ʴ��������� session ������ȡ thename ��ֵ����ʾ�����Դ�֤����Ȼ��ֵ�ڵ�һ��ҳ�����룬��ͨ�� session ������Ա����� q3.jsp ������һ����������ȡ�ڵڶ���ҳ���е��û����벢��ʾ����
< html>
< body>
< %@ page language="java" %>
< %! string food=""; %>
< %
food = request.getparameter("food");
string name = (string) session.getvalue("thename");
%>
���������ǣ� < %= name %>
< p>
��ϲ���ԣ� < %= food %>
< /body>
< /html>
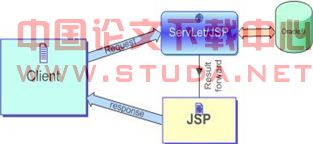
������3.2 b/sϵͳ����
������ͳ��c/s�ܹ����ͻ���/��������client/server����ʽ�У�ҵ����λ�ڿͻ��ˣ�ÿ���һ������ҪƵ���ط������ݿ⣬ʹ�����������������dz������������ӵ��û���������ʹ�á�
����Ϊ�ֲ�����c/s�ܹ���ȱ�ݣ����Ƿ�չ�����������ܹ����ͻ������м����Ӧ�÷������������ݿ������(client��middle ware��database server)�������ּܹ��У�ҵ�����������м���������ϣ�������������Ҳλ���м�������ݿ�֮�䣬���ͻ���ֻ�Ǽط��������м�����������������������������Ľ�����ظ��ͻ�������һ���͵Ŀͻ���Ҳ��֮Ϊ���C�ͻ�����b/s�ܹ�ʵ����������ܹ���һ�֣�����ͬ���ǿͻ��˾���Ŀǰ����ÿ̨�����ж��е���������������м������webӦ�÷�������ע���Ҫ��ҵ��������λ��webӦ�÷������ϵ�servlet��jsp�����ejb��������
����3.2.1 b/s�ܹ��߱��������Խ��
�����������е�Ӧ��ϵͳ�������ڻ���������ҵ�ڲ������������У���չ���������Ϊ��ҵ���ɱ������Ϣ����·��b/s�ܹ����������ǵ�������Ļ�ʯ��������������ʹ���ƶ��칫�ͷֲ�ʽЭͬ����������Ϊ��ʵ��������������Ǹ����䣬ֻ��Ҫһ̨�����������豸���������pda�����ֻ��������Է������ͻ���ϵ��������Эͬ������
����2������������ά����������ʽ�ĸ���
��������ϵͳ�ĸĽ�������Խ��ԽƵ����b/s�ܹ��IJ�Ʒ��ά������������߱����������ơ������û��Ĺ�ģ�ж���ж��ٷ�֧���������������κ�ά�������Ĺ����������еIJ���ֻ�Է��������У�ͨ��Զ�����ӷ���������ص���ά��Ա�����ڿ�������Զ��ά�������������������ʱ�䡢���õĽ�ʡ���൱���˵ġ�
�������еĿͻ���ֻ������������еIJ����������������ҳ���ƣ�ʹ���߽��ܵ���ѵҲ������ҵ���������轫���������˷�ѧϰ���������ϡ�
����3��ϵͳ����
���������ǰ칫�Զ�����oa��ϵͳ��������Դ��hr��ϵͳ���ͻ���ϵ������crm��ϵͳ��erp�ȵȣ���չ�������Dz����ںϡ�������ͳһ��b/s�ṹ�����IJ�Ʒ���������ڻ��ǽ���������õ�ѡ�����ṩ���������������������ϵͳ�������ϵķ�����
����3.2.2����java����ʵ��
��������Ŀǰwindows����ϵͳһͳ���£����Ƿ�����ϵͳ���õIJ���ϵͳȴ���ж����ԣ�����linux��unix��windows nt/2000server��ϵͳ������ʵ����ҵ��Ӧ�á�����������ϵͳ���й��������ڰ�ȫ����ս�ԵĿ��ǣ�ϣ�����Լ��IJ���ϵͳ��linux�ij���ʹ�����뷨�������ʵ��
������ͳ��c/s�ܹ���������Ҫ��Բ�ͬ�IJ���ϵͳ������ͬ�汾������������ڶ�IJ���ϵͳ���������ٵ�����������������һ�ܹ�����������������ҵ��itͶ��������һ�־�ķ��ա�������java����ʵ�ֵ�b/s�ܹ���������Ʒ���������ˡ�һ�α�д��������(write once, run anywhere)�� ,����ҵ���ԣ����Թ�ܽ�����������ϵͳ�������ķ��ա�
����2����׳��ϵͳ
����java����ʵ�ֵ�����������Ȼ�Ľ�׳�ԡ�����java�������������Ա�֤�ġ�����javaд�ɵ������������������ϵͳ�����������ǰ�ȫ��Ҫ��ܸߵ���ҵ��Ӧ�������ɻ�ȱ�����ԡ�
���������� ������ѯϵͳ��Ʒ���
�����������ݿ�ϵͳ�����ڵ���Ʒ����������ݿ�Ӧ��ϵͳ�Ϳ�����ȫ���������ǣ������ݿ�Ӧ��ϵͳ��Ʒ�Ϊ���¼����Σ�
1���滮��
2�����������
3��������ƣ�
4�������
5���������
������4.1Ӧ���������
Ҫ���һ�����õĹ�����ѯϵͳ���ͱ���������ȷ��Ӧ�û�����ϵͳ��Ҫ������ѯϵͳ��Ӧ�ñ���Ϊ�����������˹��������У��ֶ���Ŀǰ�����Զ�������������ʱ���²�ѯ���ݡ���ˣ���ϵͳ���������¼���������
1����ѯ���ܣ�ϵͳ��Ҫ�ṩ���ֲ�ͬ��ʽ�IJ�ѯ�ֶΣ���ʵ������ع�������ϵͳ��
2�����ݵĸ����ģ�
���£�ϵͳ��������Ա������û������ݽ��и��¡��IJ��Ҵ��̲�����
�༭��ϵͳ��������Ա������û������ݽ��б༭��ɾ���IJ�������֤�ֿ����ʵ����ʵʱ�ԡ�
3����ӡ�������δʵ�֣���ϵͳ���Խ��û���ѯ�������ݶ�̬�����ɱ���������ӡ�����
������4.2 ϵͳ����ģ�黮��
����������ѯϵͳ���ܻ���ģ�����£�
������ѯϵͳģ��
������ģ��ʵ�ֹ�����ѯ���ܡ���ʵ�ְ���㣭��תվ���յ��ѯ��ѯ�Ͱ���·��ѯ���ֲ�ѯ��ʽ��
����¼��ϵͳģ��
������ģ��ʵ�����ݵ�¼�롢�ġ�ɾ�����ܡ�
������4.3 ϵͳ���ݿ����
����4.3.1 �������
������Ƶ�Ŀ���Dz�����ӳ���й�����ѯϵͳ��������ݿ����ṹ��������ģʽ������ģʽ�Ƕ��������ݿ����ṹ��������֧�����ݿ��dbms���������ڼ����ϵͳ�ġ�
erģ���Ƕ���ʵ�����һ�ֳ���������Ҫ�ɷ���ʵ�塢��ϵ�����ԡ�ʹ
�������ֳɷ֣����ǿ��Խ�������Ӧ�û�����erģ�͡�
2�� erģ�͵IJ���
������erģ�ͽ������ݿ������ƵĹ����У�������Ҫ��erͼ��������
�任����Щ�任�ֳ�Ϊerģ�͵IJ���������ʵ�����͡���ϵ���ͺ����Եķ��ѡ��ϲ�����ɾ�ȵȡ�
3������er���������ݿ�������
����er�����������ݿ�ĸ�����ƣ����Էֳ��������У�������ƾֲ�erģʽ��Ȼ��Ѹ��ֲ�erģʽ�ۺϳ�һ��ȫ��erģʽ������ȫ��erģʽ�����Ż����õ����յ�erģʽ��������ģʽ��
��ƾֲ���erģʽ
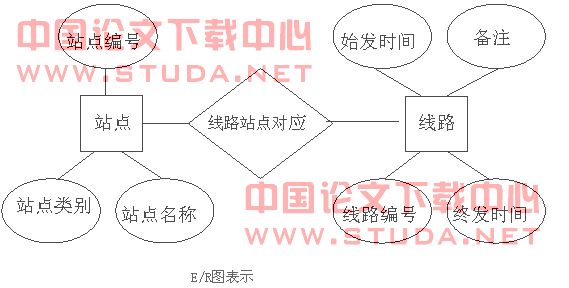
ͨ����һ�����ݿ�ϵͳ����Ϊ�����ͬ�û�����ġ������û������ݵĹ۵���ܲ�һ������Ϣ��������Ҳ���ܲ�ͬ����������ݿ����ṹʱ��Ϊ�˸��õ�ģ����ʵ���磬һ����Ч�IJ����ǡ��ֶ���֮�������ȷֱ��Ǹ����û�����Ϣ�����γɾֲ�����ṹ��Ȼ�����ۺϳ�ȫ�ֽṹ����er�����У��ֲ�����ṹ�ֳ�Ϊ�ֲ�erģʽ����ͼ�α�ʾ��Ϊerͼ��
ʵ������ԵĶ������£�
վ�㣨վ���ţ�վ�����ƣ�վ�����
��·����·��ţ�ʼ��ʱ�䣬�շ�ʱ�䣬��ע��
��·վ���Ӧ����·��ţ�վ�����ƣ�
shape \* mergeformat
e/rͼ��ʾ
����4����ϵ����
����erģ�͵ġ���ϵ�����ڿ̻�ʵ��֮��Ĺ�����һ�������ķ�ʽ�ǶԾֲ��ṹ����������ʵ�����ͣ�������������Ľ��������ֲ��ṹ����������ʵ������֮���Ƿ������ϵ��������ϵ����һ��ȷ����1:n��m:n������1:1�ȡ���Ҫ����һ��ʵ�������ڲ��Ƿ������ϵ������ʵ������֮���Ƿ������ϵ�����ʵ������֮���Ƿ������ϵ���ȵȡ�
����5�����ȫ��erģʽ
�������оֲ�erģʽ����ƺ��˺��������ǰ������ۺϳɵ�һ��ȫ�ָ���ṹ��ȫ�ָ���ṹ����Ҫ֧�����оֲ�erģʽ�����ұ�������ر�ʾһ��������һ�µ����ݿ����ṹ��
����1��ȷ������ʵ������
����Ϊ�˸�����ֲ�erģʽ�ĺϲ��ṩ��ʼ�ϲ��Ļ���������Ҫȷ�����ֲ��ṹ�еĹ���ʵ�����͡�����һ�������ǽ�����ʵ���������ͼ����϶�����ʵ�����͡�һ���ͬ��ʵ��������Ϊ����ʵ�����͵�һ���ѡ���Ѿ�����ͬ����ʵ��������Ϊ����ʵ�����͵���һ���ѡ��
����2���ֲ�erģʽ�ĺϲ�
�����ϲ���ԭ���ǣ����Ƚ��������ϲ����Ⱥͺϲ���Щ��ʵ����������ϵ�ľֲ��ṹ���ϲ��ӹ���ʵ�����Ϳ�ʼ������ټ�������ľֲ��ṹ��
����3��������ͻ
������ͻ��Ϊ���ࣺ���Գ�ͻ���ṹ��ͻ��������ͻ��
�������ȫ��erģʽ��Ŀ�IJ����ڰ����ɾֲ�erģʽ��ʽ�Ϻϲ�Ϊһ��erģʽ��������������ͻ��ʹ֮��Ϊ�ܹ��������û���ͬ����ͽ��ܵ�ͬһ�ĸ���ģ�͡�
����4��ȫ��erģʽ���Ż�
�����ڵõ�ȫ��erģʽ��Ϊ��������ݿ�ϵͳ��Ч�ʣ���Ӧ��һ�����ݴ��������erģʽ�����Ż���һ���õ�ȫ��erģʽ������ȷ��ȫ��ط�ӳ�û����������⣬��Ӧ��������������ʵ�����͵ĸ���Ҫ�����ܵ��٣�ʵ�������������Ը����������٣�ʵ�����ͼ���ϵ�����ࡣ
����4.3.2�����
�������ڸ�����ƵĽ����erͼ��dbmsһ����ù�ϵ�ͣ�������ݿ������ƹ��̾��ǰ�erͼת��Ϊ��ϵģʽ�Ĺ��̡����ڹ�ϵģ���е��ŵ㣬����ƿ��Գ�����ù�ϵ���ݿ�淶�����ۣ�ʹ��ƹ�����ʽ���ؽ��С���ƽ����һ���ϵģʽ�Ķ��塣
����1��������ʼ��ϵģʽ
����2����ϵ��ģʽ
������ģʽ���û����õ����Dz������ݵ�����������ָ���û��õ��������⣬��Ӧָ�����������ģʽ����Ӧ���ݵ���ϵ����ָ������ģʽ����ģʽ֮��Ķ�Ӧ�ԡ�
���������� ������ѯϵͳӦ�ó�����ƣ����֣�
����<%@ page contenttype="text/html; charset=iso8859_1" %>
����<%@ page import="java.sql.*,java.util.*,com.lanyuer.util.*;" %>
<%
list routes = null;
connection connection;
com.lanyuer.route.route_manager route_manager = com.lanyuer.route.route_manager.getinstance();
connection = dataconnectionmanager.getinstance().getconnection();
try {
routes = route_manager.selectes(connection);
} catch (exception e) {
throw e;
} finally {
if (connection != null) {
connection.close();
connection = null;
}
}
%>